반응형
DB HA(고가용성)란? — 개념부터 아키텍처·운영 체크리스트까지
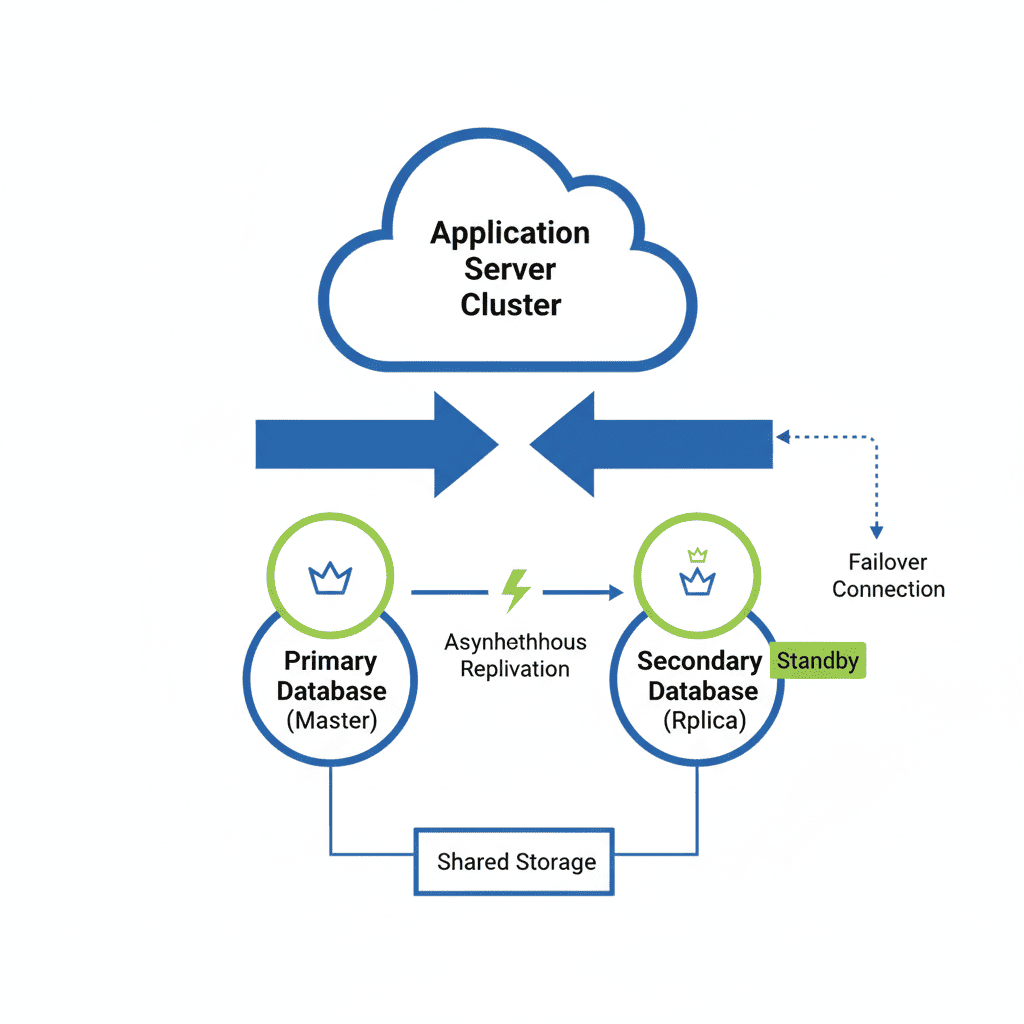
DB HA(High Availability, 고가용성)는 데이터베이스 서비스가 장애 복구·유지보수 상황에서도 중단 없이 동작하도록 설계하는 일체의 기술과 운영 절차입니다.
이 글에서는 핵심 개념, 주요 아키텍처, 핵심 지표(RTO/RPO) 및 실무 팁을 쉽게 정리합니다.
한눈에 요약
- DB HA = 가용성(Availability)·내결함성(Fault Tolerance)·복구 능력(Recovery)을 보장하는 설계·운영의 총합
- 핵심 목표: 서비스 다운타임 최소화, 데이터 손실 최소화
- 주요 방식: 복제(Replication), 페일오버(Failover), 클러스터링(Sharding 포함), 리플리케이션 + 로드밸런서
- 운영 포인트: 모니터링·자동화·테스트(예: 페일오버 리허설)가 필수
1. DB HA의 핵심 개념
고가용성(HA)은 단순한 복제만을 뜻하지 않습니다. 장애를 자동으로 감지하고(모니터링), 대체 노드로 트래픽을 전환(페일오버), 데이터 일관성과 회복을 보장(복제·동기/비동기)하는 전반적 설계와 운영을 포함합니다.
용어 정리 — Failover(장애 발생 시 대체로 전환), Failback(원상 복구 후 되돌리기), Replication(데이터 복제), Quorum(합의) 등.
2. 핵심 지표: RTO & RPO
- RTO (Recovery Time Objective): 장애 발생 후 서비스를 복구하는 데 허용되는 최대 시간(목표 복구 시간)
- RPO (Recovery Point Objective): 허용 가능한 데이터 손실량(마지막 복구 시점부터 얼마나 뒤로 돌아갈 수 있는지)
설계 시 RTO/RPO 요구사항에 따라 '동기 복제 vs 비동기 복제', 페일오버 자동화 수준, DR(재난복구) 전략을 결정합니다.
3. 주요 HA 아키텍처 유형
- Active-Passive (Master-Slave) — 쓰기 마스터, 읽기/백업용 슬레이브. 마스터 장애 시 슬레이브 승격(페일오버). 구현 단순, 쓰기 지점은 단일.
- Active-Active (Multi-Master) — 여러 쓰기 노드가 동시에 활성. 충돌 해결과 데이터 일관성 보장이 필요(예: Galera Cluster, Cassandra).
- Replication + Load Balancer — 읽기 트래픽 분산, 쓰기는 마스터로. 클라이언트는 LB나 프록시를 통해 마스터 위치를 투명하게 참조.
- Shared-Nothing Cluster / Sharding — 데이터 샤딩으로 확장성과 가용성 확보(예: MongoDB Shard, MySQL Sharding 솔루션)
- Managed Cloud DB (RDS 등) — 클라우드 제공업체의 HA 기능(다중 AZ, 자동 페일오버)을 활용하는 방식
4. 실사용 예시 (제품/솔루션)
- MySQL: 복제 + MHA/Orchestrator/ProxySQL/HAProxy로 페일오버 및 라우팅
- PostgreSQL: Streaming Replication + Patroni + HAProxy/pgpool-II
- MariaDB / Galera: 멀티마스터 동기 클러스터(Galera) — 읽기/쓰기 분산
- Redis: Sentinel(HA 자동 페일오버), Cluster(샤딩 + HA)
- Cassandra / Scylla: 분산형 Active-Active 모델(내결함성 우수)
- Managed DB: AWS RDS Multi-AZ, Cloud SQL 등 — 운영 관리 부담 경감
5. 각 방식별 장단점(요약)
| 아키텍처 | 장점 | 단점 |
|---|---|---|
| Active-Passive | 단순 설계, 데이터 일관성 관리 쉬움 | 마스터 SPOF 가능, 수동/자동 페일오버 필요 |
| Active-Active | 쓰기/읽기 확장 우수, 무중단 운영 가능 | 충돌 해결·복잡한 일관성 설계 필요 |
| Managed DB | 운영 부담 감소, SLA 보장 | 비용 증가, 커스터마이징 제약 |
6. 설계 시 고려사항
- RTO/RPO 요구사항에 따른 동기/비동기 복제 선택
- 데이터 일관성(강한 일관성 vs 최종적 일관성) 요구 수준
- 네트워크 레이턴시와 리플리케이션 지연 — 리전/가용영역(Zone) 고려
- 클라이언트 재연결·재시도 로직 — 애플리케이션 레이어에서 idempotency 보장
- 오퍼레이션 자동화 — 자동 페일오버, 헬스체크, 모니터링·알람
- 테스트 계획 — 정기적 페일오버 리허설(Chaos engineering)
7. 운영·모니터링 팁
- 헬스 체크(메모리·디스크·레플리케이션 지연)를 통합 모니터링
- 자동화된 알람(페일오버·복제 지연·디스크 부족 등) 설정
- 정기 백업과 백업 복원 검증(복원 시간 측정)
- 롤링 업데이트·패치 전략: 전체 서비스 중단 없이 노드 교체
- DR(재난복구) 계획: 리전 단위 장애를 대비한 복제/복구 플랜
8. HA 도입 체크리스트 (실무용)
- 비즈니스 요구에 맞춘 RTO/RPO 정의
- 적절한 아키텍처(Active-Passive / Active-Active / Managed) 선택
- 복제·페일오버 매커니즘(자동/수동) 결정 및 테스트
- 모니터링·알람·로그 수집 체계 구축
- 백업·복원 및 DR 시나리오 문서화
- 정기적인 장애 복구 연습(페일오버 리허설)
마무리 — HA는 기술 + 운영의 결합
DB HA는 단순히 복제 솔루션을 도입하는 것을 넘어, 요구사항 분석 → 아키텍처 선택 → 자동화·모니터링 → 반복적 테스트을 통해 실질적인 가용성을 확보하는 과정입니다. 작은 서비스는 Managed DB나 단순 복제로도 충분할 수 있고, 미션 크리티컬 환경은 복잡한 클러스터·DR 설계가 필요합니다. 항상 테스트와 문서화를 병행하세요.
반응형
'개발 · IT > 백엔드' 카테고리의 다른 글
| PM2로 Node 서버 운영하기 — 설치부터 운영·모니터링·무중단 배포까지 (0) | 2025.11.21 |
|---|---|
| Express 미들웨어 실행 순서 완전 정리 (0) | 2025.11.21 |
| Redis Sentinel 구조 완전 정리 — 개념 · 구성 요소 · 페일오버 흐름 (0) | 2025.11.19 |
| Redis TTL & SETEX 완전 정리 — 개념 · 명령어 · 실전 예제 (0) | 2025.11.19 |
| Redis 캐싱 구조와 활용 예제 (0) | 2025.11.18 |




댓글