
안녕하세요 오늘은 그라파나와 프로메테우스 노드 익스포터를 이용한 실시간 서버 모니터링 실습을 진행해보겠습니다.
먼저 각각의 툴을 설명하겠습니다.
- 그라파나(Grafana): 그라파나는 오픈소스 대시보드 및 시각화 플랫폼입니다. 특히 시계열 데이터에 대한 대시보드를 만드는 데 매우 유용합니다. 그라파나를 사용하면 데이터를 쉽게 쿼리할 수 있으며, 결과를 그래프, 히스토그램, 히트맵 등 다양한 형태로 시각화할 수 있습니다.
- 프로메테우스(Prometheus): 프로메테우스는 오픈소스 모니터링 및 알림 툴입니다. 주로 시계열 데이터를 모니터링하며, 데이터를 수집하고 저장하는 데 사용됩니다. 프로메테우스는 다양한 서비스를 모니터링하고, 이에 대한 메트릭을 시간에 따라 추적할 수 있습니다.
- 노드 익스포터(Node Exporter): 노드 익스포터는 프로메테우스의 공식 시스템 모니터링 에이전트입니다. 노드 익스포터는 호스트의 운영 체제 메트릭을 수집하여 프로메테우스 서버로 전송합니다. 이를 통해 CPU 사용률, 메모리 사용량, 디스크 I/O, 네트워크 통계 등 다양한 시스템 정보를 모니터링할 수 있습니다.
먼저 그라파나를 다운로드 받겠습니다.
https://grafana.com/grafana/download?platform=windows
Download Grafana | Grafana Labs
Overview of how to download and install different versions of Grafana on different operating systems.
grafana.com
가동할 OS에 맞게 다운로드 받아주세요 저는 윈도우로 실행해보겠습니다.
다운로드를 완료하고 localhost:3000으로 들어가면 그라파나 대시보드를 확인 할 수 있습니다.
아이디 비번은 admin입니다.
이번엔 프로메테우스를 받아봅시다.
https://prometheus.io/download/
Download | Prometheus
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
프로메테우스는 다양한 모니터링 에이전트를 제공하는데 여기서
node_exporter
도 같이받아줍니다.
이제 노드 익스포터를 모니터링 하고 싶은 서버에 깔아줍니다.
쉘스크립트를 하나 만들어서 노드익스포터의 포트를 내가 원하는곳에서 리슨할 수 있게 해줍니다. 저는 9090으로 설정해줬습니다.
이제 다시 프로메테우스로 와서 yml을 설정해줍니다.
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['211.238.138.219:9090']
labels:
instance: '219_rcs_dev'
- targets: ['211.238.138.217:9090']
labels:
instance: '217_ptp_dev'
해당 서버의 이름을 지정해서 알아보기 쉽게 해주면 됩니다. 위의 명칭은 예시입니다.
이제 그라파나로 와서 datasource에 프로메테우스를 연결해줍니다.
대시보드탭으로 가서 cpu 사용률이라는 모니터링을 한번 만들어보겠습니다.
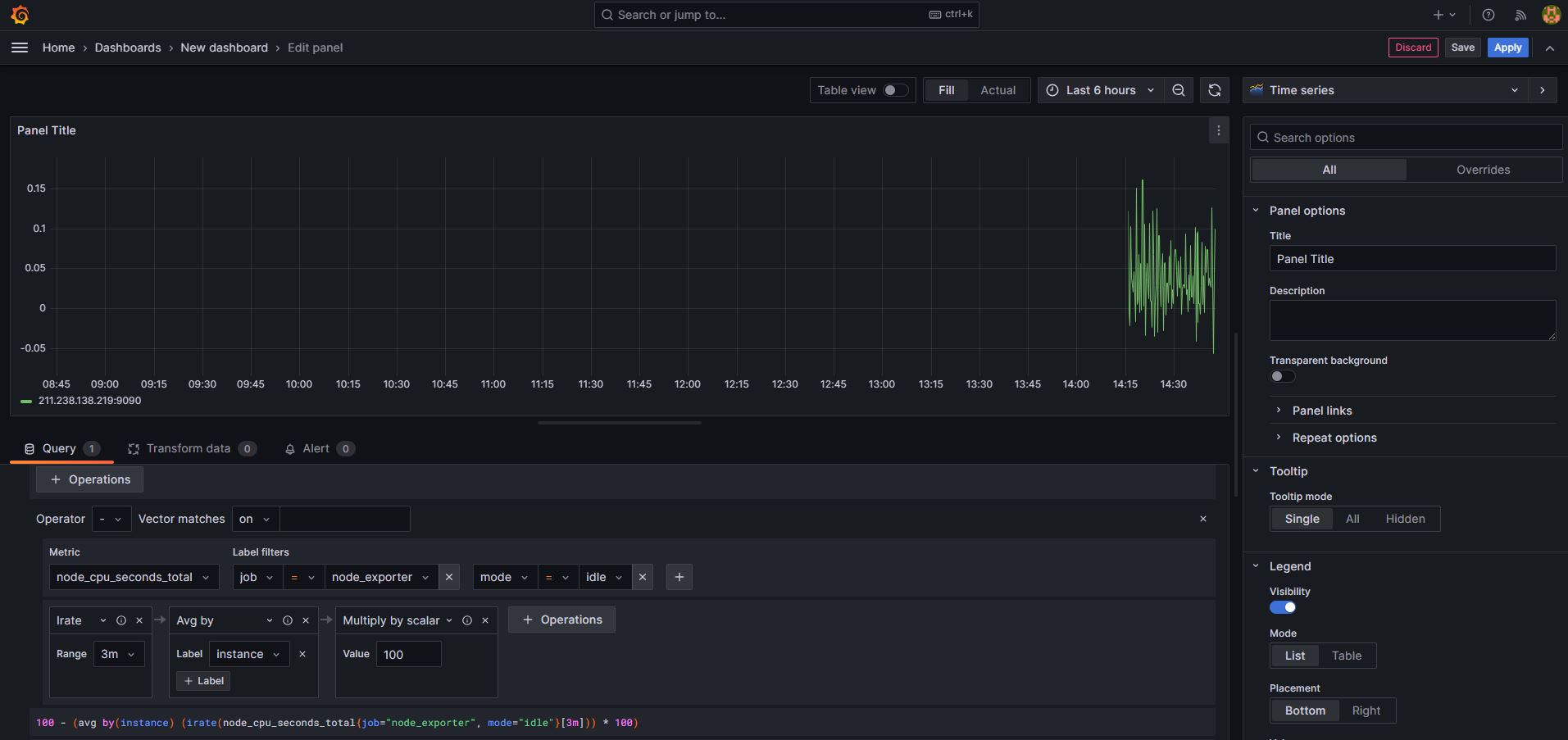
panel을 edit하는 부분에서 쿼리를 사용해야합니다.
100 - (avg by (instance) (irate(node_cpu_seconds_total{job="node_exporter",mode="idle"}[3m])) * 100)
해당 쿼리를 사용하면 cpu 사용률을 알 수 있습니다.
같은 방식으로
메모리 사용률 : 100 * (1 - ((avg_over_time(node_memory_MemFree_bytes{job="$val_job"}[1m]) + avg_over_time(node_memory_Cached_bytes{job="$val_job"}[1m]) + avg_over_time(node_memory_Buffers_bytes{job="$val_job"}[1m])) / avg_over_time(node_memory_MemTotal_bytes{job="$val_job"}[1m])))
디스크 사용률 : 100 - (100 * ((node_filesystem_avail_bytes{job="$val_job"}) / (node_filesystem_size_bytes{job="$val_job"})))
아이노드 사용률 : 100 - ((node_filesystem_files_free{job="$val_job"}) / (node_filesystem_files{job="$val_job"}) * 100)
네트워크 트래픽 : irate(node_network_transmit_bytes_total{instance="$val_host",job="$val_job"}[5m])*8
대시보드를 꾸며 봅시다.
최종적으로 우리는 서버들을 모니터링 할 수 있게 되었습니다!!
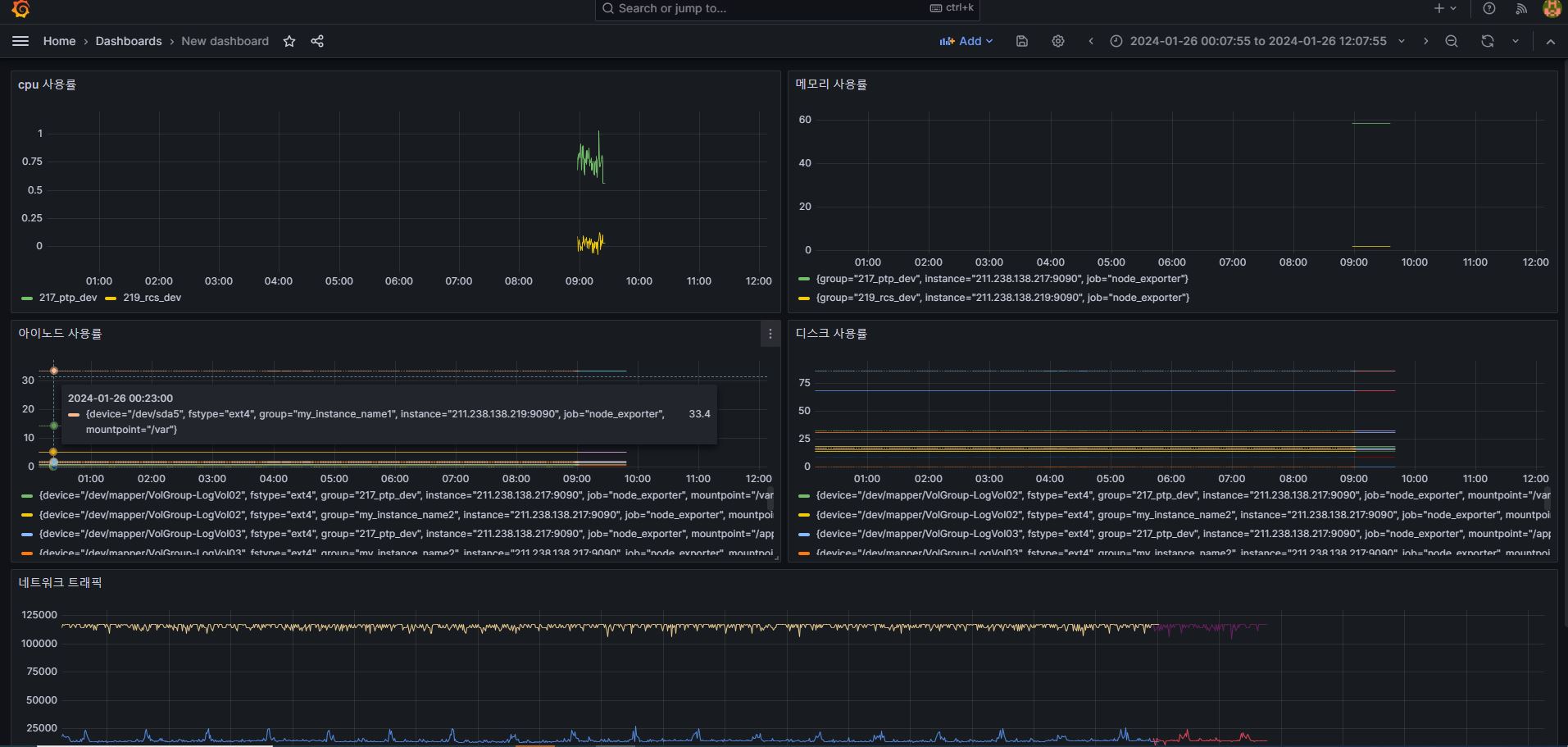
이것은 빙산의 일각입니다. 더욱더 다양한 모니터링 방법이 있습니다.
앞으로도 공부하여 새로운 사실을 알게되면 공유하겠습니다.
감사합니다.
'개발 · IT > 시스템 · 인프라' 카테고리의 다른 글
| 버츄얼 박스 windows 세팅 Q&A (0) | 2024.03.10 |
|---|---|
| 마리아 DB 레플리카 기능 써보기 (1) | 2024.02.25 |
| Git 브랜치 전환과 관련된 모든 것: 이해하기 쉬운 가이드 (0) | 2023.11.04 |
| 리눅스 grep vs egrep 골라 써보자 (0) | 2023.11.04 |
| 리눅스에서 로그 보는법 (0) | 2023.11.04 |

댓글